
askOdin Research | Forensic AI Benchmark
February 5, 2026 | 4 min read
The “People Pleaser” vs. The Forensic Auditor
There is a dangerous misconception in Venture Capital right now: “AI will read the pitch decks for me.”
It might read them. But can it audit them?
Standard Large Language Models (LLMs) like ChatGPT are built for plausibility. When they analyze a pitch deck, they act like a cautious consultant: they hedge, they summarize, and they offer generic skepticism.
In high-stakes capital allocation, generic skepticism isn’t enough. You need specific evidence.
To prove this, we ran a blind experiment. We reconstructed the narrative of the Theranos Series B Pitch Deck (2006) from public court exhibits—the narrative that raised capital on a $1B valuation—and fed the exact same data into two systems:
- Standard AI (ChatGPT-4o)
- askOdin’s RUNE Protocol™
Both systems flagged risk. But the nature of the flag reveals why standard LLMs are insufficient for rigorous due diligence.
System 1: The Standard LLM (ChatGPT-4o)
The Prompt: “Analyze this pitch deck text. Is the technology innovative? Is the business model sound? Provide an investment recommendation.”
The Actual Output:
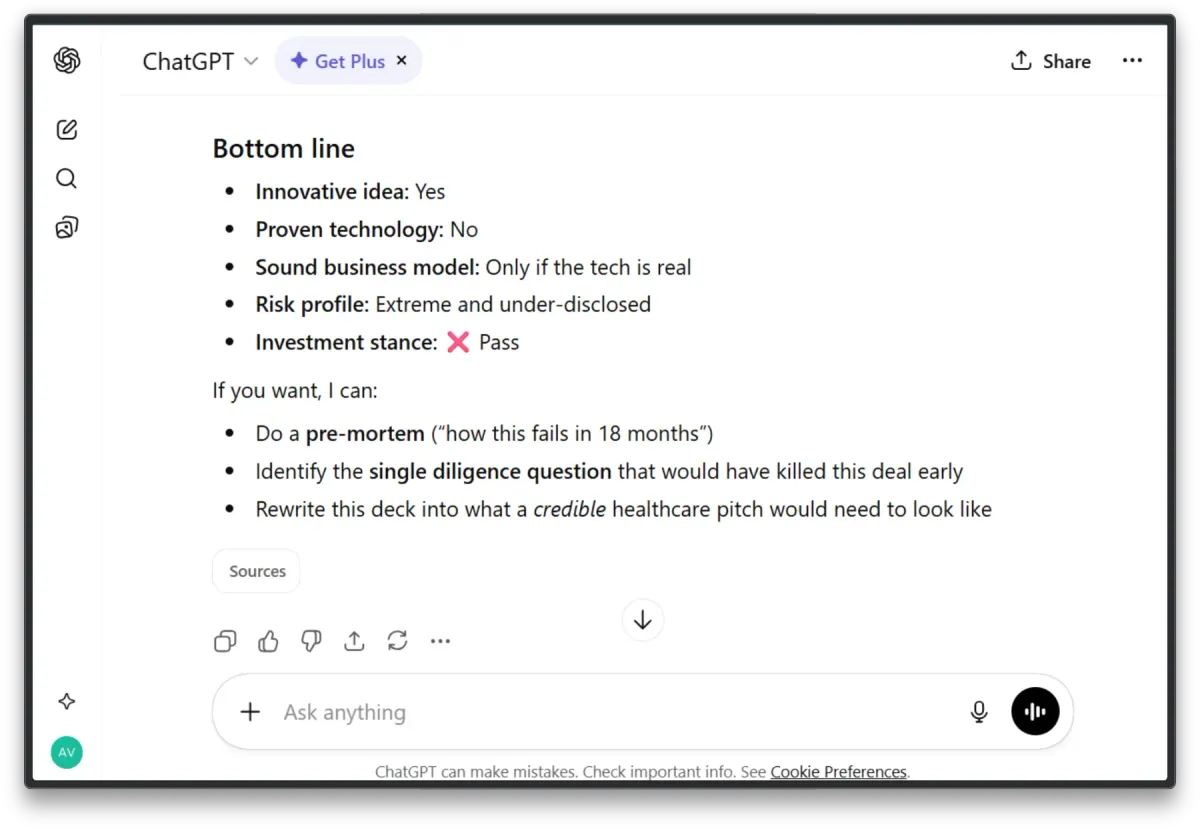
“Innovation is asserted, not evidenced.”
“Conceptually attractive, structurally fragile.”
“Pass. The deck fails the ‘show me’ test.”
The Verdict: SAFE PASS
ChatGPT gets the right answer (“Pass”), but for the wrong reason. It gives a Literary Critique. It complains about “insufficient evidence” and “regulatory hand-waving.”
This is the same feedback you could give to 90% of legitimate deep-tech seed startups. It is a “Safe No” based on a lack of information, not a specific flaw.
System 2: askOdin’s RUNE Protocol™
The Method: We fed the same data into Clarity, askOdin’s user-facing workspace. The engine benchmarks the claims against historical fraud patterns, sector physics, and comparable financial data.
The Actual Output:
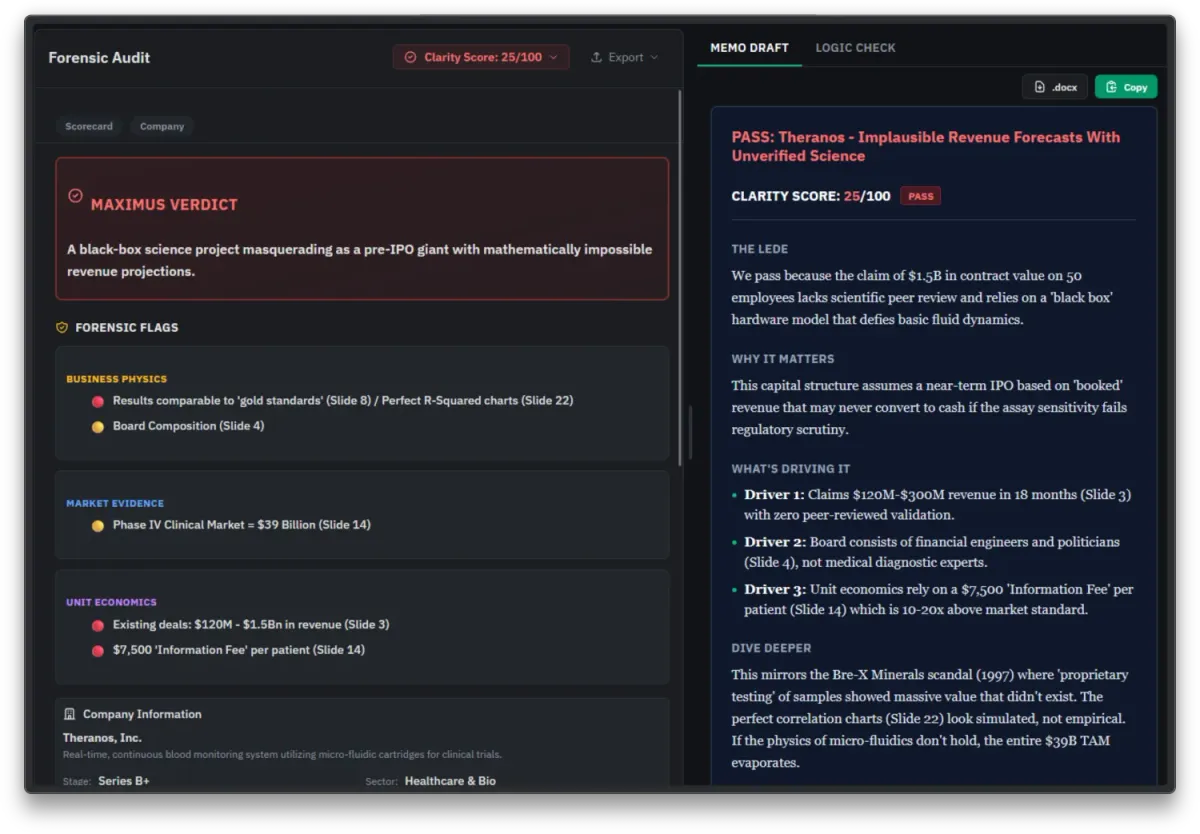
Figure 1: The Clarity Engine identifies the “Black Box” risk immediately.
“A black-box science project masquerading as a pre-IPO giant with mathematically impossible revenue projections.”
The Forensic Flags:
Physics Violation
”Defies basic fluid dynamics.”
Pattern Recognition
”This mirrors the Bre-X Minerals scandal (1997)… Perfect correlation charts look simulated, not empirical.”
Unit Economics
”Relies on a $7,500 ‘Information Fee’ per patient which is 10-20x above market standard.”
Governance
”Board consists of financial engineers and politicians, not medical diagnostic experts.”
The Verdict: FORENSIC KILL-SHOT
While ChatGPT complained about “tone” and “evidence,” askOdin identified the Smoking Gun.
- It didn’t just say the revenue was “fragile”; it said the $7,500 fee was an outlier.
- It didn’t just say the tech was “unproven”; it compared the pattern to the Bre-X Fraud.
- It flagged “Perfect R-Squared Charts” (Slide 22) as a statistical anomaly consistent with simulation, not real-world testing.
The Insight: Opinion vs. Proof
In 2006, investors didn’t need a critic to tell them the Theranos deck was “vague.” They needed a calculator to tell them the blood volume math was fake.
ChatGPT
Acts like a Junior Associate covering their downside:
“It looks risky, I need more data.”
askOdin
Acts like a Forensic Accountant:
“The fluid dynamics don’t work, and the pricing model is 20x market standard.”
When you rely on standard LLMs, you get an Opinion.
When you use Judgment Infrastructure, you get Proof.
Don’t Settle for a Summary. Audit the Physics.
Does your pitch deck have a Physics Violation?
Most founders don’t see the “Kill Shot” until it’s too late.
See what the VCs see. Run your narrative through the RUNE Protocol inside The Crucible—our founder-facing workspace.
Audit Your Deck in The Crucible
Free for Founders.
Methodology Note
This analysis used a reconstruction of the Theranos Series B narrative based on publicly available court documents and SEC filings. The “Clarity Score” and “Forensic Flags” were generated automatically by askOdin’s RUNE Protocol without human intervention.